GRAFANA est une solution libre qui permet de réaliser des mises en forme de données métriques. Dans cet article nous allons configurer GRAFANA pour afficher des tableaux de bords (Dashboards) dédié à VMware dans le but de superviser notre infrastructure.
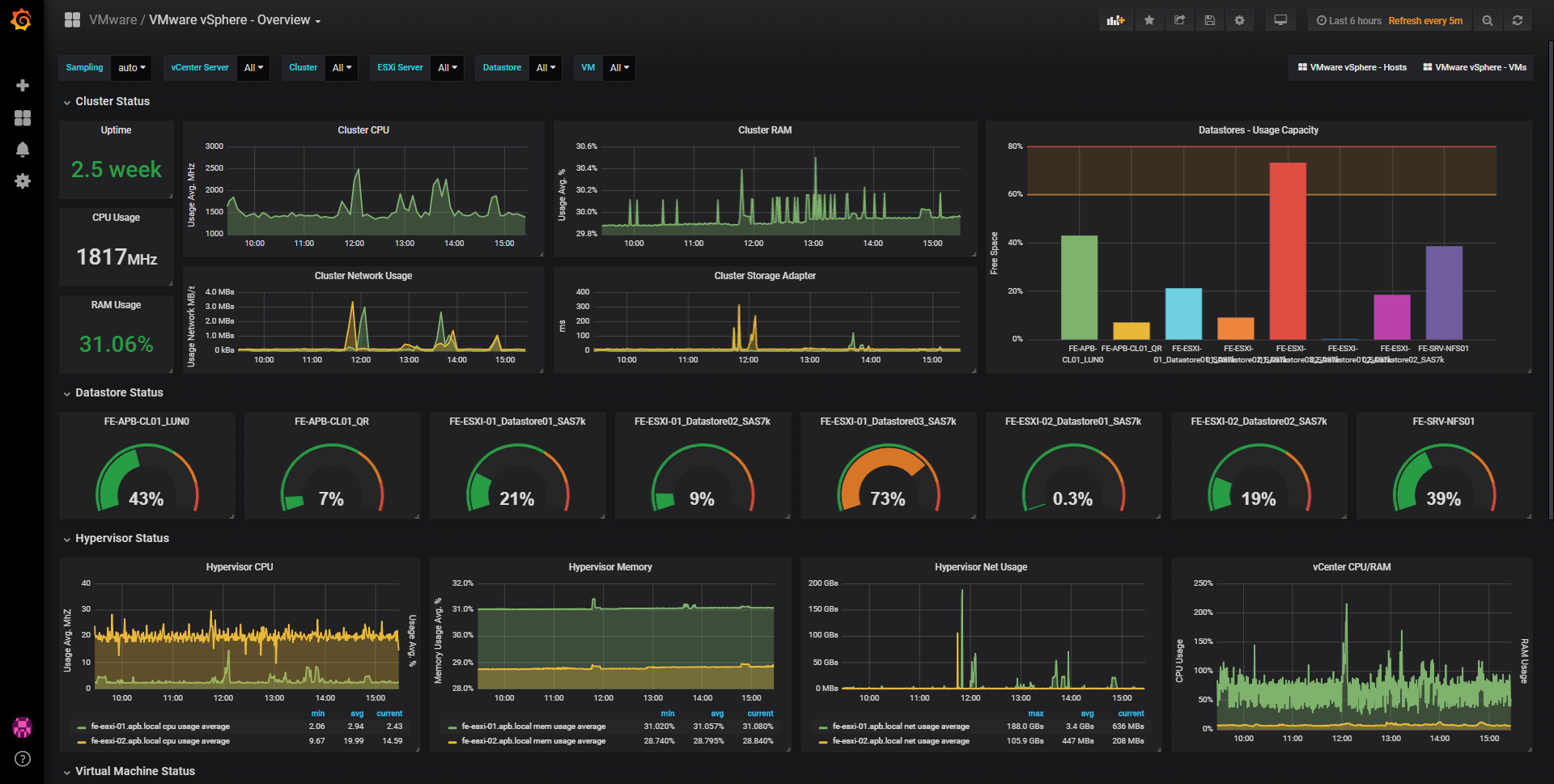
Exemple de tableau de bord :
Prérequis
Dans mon exemple, j'installerai GRAFANA sur un serveur Debian 9.6 x64 avec une installation de base. L'ensemble des services seront hébergés sur un seul et même serveur.
Il est nécessaire d'avoir un serveur vCenter opérationnel et un compte ayant un accès en lecture seul sur l'ensemble des éléments à superviser.
Procédure
L'installation nécessite 3 éléments :
- GRAFANA pour la mise en forme.
- InfluxDB pour le stockage des données.
- Telegraf pour la collecte de données.
L'ensemble des actions à réaliser nécessite d'avoir les privilèges administrateur.
Installation de InfluxDB
# cd /tmp # wget https://dl.influxdata.com/influxdb/releases/influxdb_1.7.2_amd64.deb # dpkg -i influxdb_1.7.2_amd64.deb # systemctl start influxd # systemctl status influxd
Configuration de InfluxDB
Adapter le nom de la base de données, l'utilisateur, le mot de passe et la politique de rétention des données suivant vos besoins.
# influx -execute "CREATE DATABASE influx_db_telegraf # influx -execute "CREATE USER user_telegraf WITH PASSWORD 'password'" # influx -execute "CREATE RETENTION POLICY "a_year" ON "influx_db_telegraf" DURATION 52w REPLICATION 1 DEFAULT" # influx -execute "GRANT ALL ON influx_db_telegraf TO user_telegraf"
Installation de Telegraf
# cd /tmp # wget https://dl.influxdata.com/telegraf/releases/telegraf_1.9.1-1_amd64.deb # dpkg -i telegraf_1.9.1-1_amd64.deb
Configuration de Telegraf
# nano /etc/telegraf/telegraf.conf
Ajouter les informations de connexion à la base de données InfluxDB en éditant le fichier de cette façon :
[[outputs.influxdb]] ## The full HTTP or UDP URL for your InfluxDB instance. ## ## Multiple URLs can be specified for a single cluster, only ONE of the ## urls will be written to each interval. # urls = ["unix:///var/run/influxdb.sock"] # urls = ["udp://127.0.0.1:8089"] # urls = ["http://127.0.0.1:8086"] ## The target database for metrics; will be created as needed. # database = "telegraf" database = "influx_db_telegraf" username = "user_telegraf" password = "password"
Pour pouvoir collecter les informations de votre infrastructure VMware, il est nécessaire d'ajouter à la fin du fichier /etc/telegraf/telegraf.conf les informations suivantes (modifier les informations de connexions à votre/vos vCenter) :
# Read metrics from one or many vCenters [[inputs.vsphere]] ## List of vCenter URLs to be monitored. These three lines must be uncommented ## and edited for the plugin to work. vcenters = [ "https://vcenter.apb.local/sdk" ] username = "grafana@vsphere.local" password = "grafanapassword" ## VMs ## Typical VM metrics (if omitted or empty, all metrics are collected) vm_metric_include = [ "cpu.demand.average", "cpu.idle.summation", "cpu.latency.average", "cpu.readiness.average", "cpu.ready.summation", "cpu.run.summation", "cpu.usagemhz.average", "cpu.used.summation", "cpu.wait.summation", "mem.active.average", "mem.granted.average", "mem.latency.average", "mem.swapin.average", "mem.swapinRate.average", "mem.swapout.average", "mem.swapoutRate.average", "mem.usage.average", "mem.vmmemctl.average", "net.bytesRx.average", "net.bytesTx.average", "net.droppedRx.summation", "net.droppedTx.summation", "net.usage.average", "power.power.average", "virtualDisk.numberReadAveraged.average", "virtualDisk.numberWriteAveraged.average", "virtualDisk.read.average", "virtualDisk.readOIO.latest", "virtualDisk.throughput.usage.average", "virtualDisk.totalReadLatency.average", "virtualDisk.totalWriteLatency.average", "virtualDisk.write.average", "virtualDisk.writeOIO.latest", "sys.uptime.latest", ] # vm_metric_exclude = [] ## Nothing is excluded by default # vm_instances = true ## true by default ## Hosts ## Typical host metrics (if omitted or empty, all metrics are collected) host_metric_include = [ "cpu.coreUtilization.average", "cpu.costop.summation", "cpu.demand.average", "cpu.idle.summation", "cpu.latency.average", "cpu.readiness.average", "cpu.ready.summation", "cpu.swapwait.summation", "cpu.usage.average", "cpu.usagemhz.average", "cpu.used.summation", "cpu.utilization.average", "cpu.wait.summation", "disk.deviceReadLatency.average", "disk.deviceWriteLatency.average", "disk.kernelReadLatency.average", "disk.kernelWriteLatency.average", "disk.numberReadAveraged.average", "disk.numberWriteAveraged.average", "disk.read.average", "disk.totalReadLatency.average", "disk.totalWriteLatency.average", "disk.write.average", "mem.active.average", "mem.latency.average", "mem.state.latest", "mem.swapin.average", "mem.swapinRate.average", "mem.swapout.average", "mem.swapoutRate.average", "mem.totalCapacity.average", "mem.usage.average", "mem.vmmemctl.average", "net.bytesRx.average", "net.bytesTx.average", "net.droppedRx.summation", "net.droppedTx.summation", "net.errorsRx.summation", "net.errorsTx.summation", "net.usage.average", "power.power.average", "storageAdapter.numberReadAveraged.average", "storageAdapter.numberWriteAveraged.average", "storageAdapter.read.average", "storageAdapter.write.average", "sys.uptime.latest", ] # host_metric_exclude = [] ## Nothing excluded by default # host_instances = true ## true by default ## Clusters cluster_metric_include = [] ## if omitted or empty, all metrics are collected # cluster_metric_exclude = [] ## Nothing excluded by default # cluster_instances = true ## true by default ## Datastores datastore_metric_include = [] ## if omitted or empty, all metrics are collected # datastore_metric_exclude = [] ## Nothing excluded by default # datastore_instances = false ## false by default for Datastores only ## Datacenters datacenter_metric_include = [] ## if omitted or empty, all metrics are collected # datacenter_metric_exclude = [ "*" ] ## Datacenters are not collected by default. # datacenter_instances = false ## false by default for Datastores only ## Plugin Settings ## separator character to use for measurement and field names (default: "_") # separator = "_" ## number of objects to retreive per query for realtime resources (vms and hosts) ## set to 64 for vCenter 5.5 and 6.0 (default: 256) # max_query_objects = 256 ## number of metrics to retreive per query for non-realtime resources (clusters and datastores) ## set to 64 for vCenter 5.5 and 6.0 (default: 256) # max_query_metrics = 256 ## number of go routines to use for collection and discovery of objects and metrics # collect_concurrency = 1 # discover_concurrency = 1 ## whether or not to force discovery of new objects on initial gather call before collecting metrics ## when true for large environments this may cause errors for time elapsed while collecting metrics ## when false (default) the first collection cycle may result in no or limited metrics while objects are discovered # force_discover_on_init = false ## the interval before (re)discovering objects subject to metrics collection (default: 300s) # object_discovery_interval = "300s" ## timeout applies to any of the api request made to vcenter # timeout = "20s" ## Optional SSL Config # ssl_ca = "/path/to/cafile" # ssl_cert = "/path/to/certfile" # ssl_key = "/path/to/keyfile" ## Use SSL but skip chain & host verification insecure_skip_verify = true
Démarrage du service telegraf
# systemctl start telegraf # systemctl status telegraf # systemctl enable telegraf
Installation de GRAFANA
# cd /tmp # apt-get install libfontconfig # wget https://dl.grafana.com/oss/release/grafana_5.4.2_amd64.deb # dpkg -i grafana_5.4.2_amd64.deb # systemctl daemon-reload # systemctl enable grafana-server # systemctl start grafana-server # systemctl status grafana-server
Configuration de GRAFANA
1) Depuis un navigateur WEB, se connecter sur l'adresse suivante : http://IP_SRV_GRAFANA:3000.

2) Se connecter à GRAFANA avec le compte admin. Le mot de passe par défaut est admin. Changer le si vous le souhaitez.
3) Cliquer sur Configuration puis Data Sources.
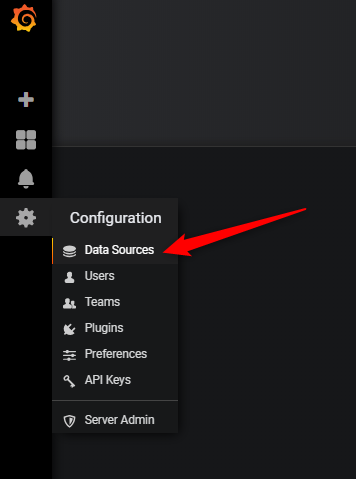
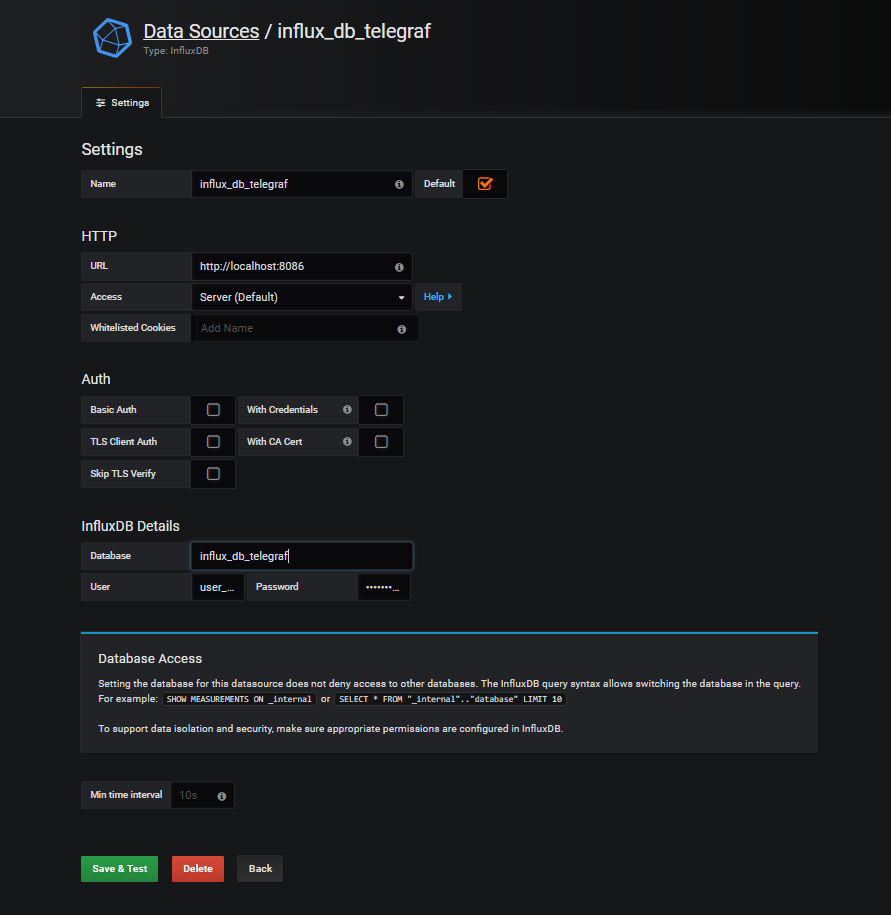
4) Cliquer sur Add data source, sélectionner InfluxDB puis renseigner les informations de connexions. Une fois les champs renseignés, cliquer sur Save & Test pour valider le bon fonctionnement.
5) Il ne reste plus qu'a créer vos tableaux de bords (Dashboards) ou importer des existants. Ils sont disponible depuis le site de GRAFANA ICI.
Les dashboards que j'utilise sont les suivants :
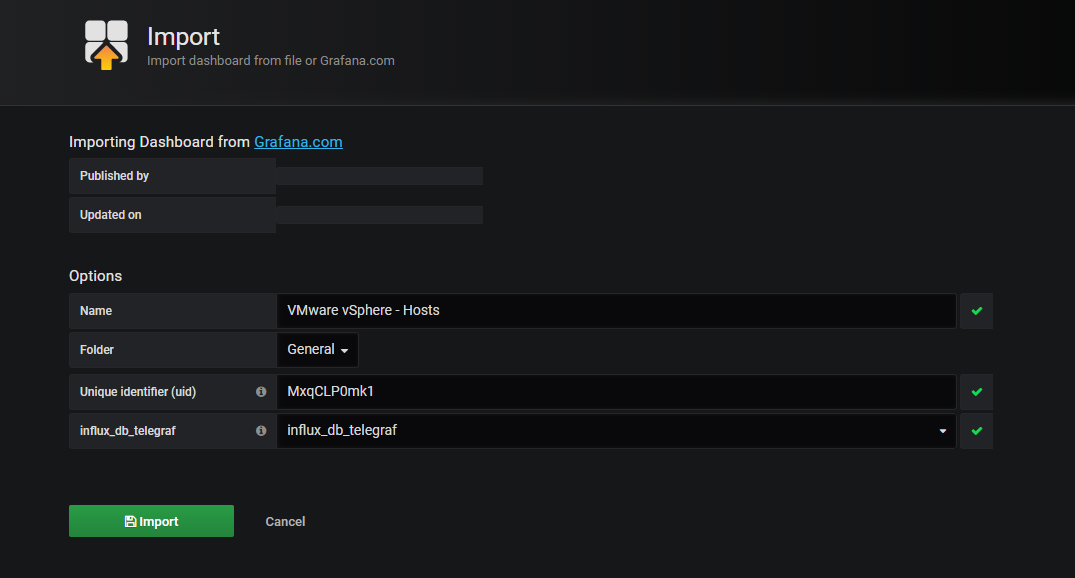
Pour importer un tableau de bord, cliquer sur le + en haut à gauche, Import, puis Upload .json File. Lors de l'importation, sélectionner la bonne source de données.
Exemple :
Hello, j'ai une question... Et je ne retrouve rien sur internet.. comment je rajoute un vcenter avec des identifiants differents?
Merci de votre reponse.
Bryce